-
PYTHON > scanner, analyser et parser une page HTML
TÉLÉCHARGER UNE PAGE HTML
pip install requests bs4
import requests response = requests.get('https://api.github.com') if response.status_code == 200: print('OK') elif response.status_code == 404: print('Erreur 404')
200= OK,204= pas de contenu,304= not modified,403=non autorisé,404= non touvéfrom requests.exceptions import HTTPError for url in ['https://api.github.com', 'https://api.github.com/invalid']: try: response = requests.get(url) response.raise_for_status() # If the response was successful, no Exception will be raised except HTTPError as http_err: print(f'HTTP error occurred: {http_err}') except Exception as err: print(f'Other error occurred: {err}') else: print('Success')
.content: pour voir le contenu en bytes :
response.content
response.text
le renvoi est retourné en JSON .
Pour un retour en dictionnaire : .json():
response.json() {'current_user_url': 'https://.../user', 'followers_url': 'http://.../order'}On accède à chaque valeur par une clé objet.
Headers
response.headers
response.headers['content-type'] 'application/json; charset=utf-8'Passer des arguments à GET
response = requests.get(url, params={'q': 'requests+language:python'}, ) # Inspect some attributes of the `requests` repository json_response = response.json() repository = json_response['items'][0] print(f'Repository name: {repository["name"]}') # Python 3.6+ print(f'Repository description: {repository["description"]}') # Python 3.6+You can pass params to get() in the form of a dictionary, as you have just done, or as a list of tuples:
requests.get(url, params=[('q', 'requests+language:python')], )You can even pass the values as bytes:
requests.get(url, params=b'q=requests+language:python', )Headers
response = requests.get(url, params={'q': 'requests+language:python'}, headers={'Accept': 'application/vnd.github.v3.text-match+json'}, )Accept header tells the server what content types your application can handle.
Other HTTP Methods
requests.post(url, data={'key':'value'}) requests.put(url, data={'key':'value'}) requests.delete(url) requests.head(url) requests.patch(url, data={'key':'value'}) requests.options(url')response = requests.head(url) response.headers['Content-Type'] 'application/json' response = requests.delete(url) json_response = response.json() json_response['args'] {}
The Message Body
requests.post(url, data={'key':'value'})requests.post(url, data=[('key', 'value')])Pour envoyer du JSON :
response = requests.post(url, json={'key':'value'}) json_response = response.json() json_response['data'] '{"key": "value"}' json_response['headers']['Content-Type'] 'application/json'Authentication
from getpass import getpass requests.get(url, auth=('username', getpass()))requests.get(url) <Response [401]>Therefore, you could make the same request by passing explicit Basic authentication credentials using HTTPBasicAuth:
from requests.auth import HTTPBasicAuth from getpass import getpass requests.get(url, auth=HTTPBasicAuth('username', getpass()) )SSL
SSL est actif par défaut. Pour le désactiver, you pass False to the verify parameter of the request function:
requests.get(url, verify=False)Timeouts
requests.get(url, timeout=3) # attend 3 secondes
Si la connexion échoue au bout de 2 secondes d’attente, et la réponse met plus de 5 secondes à arriver :
requests.get(url, timeout=(2, 5))
from requests.exceptions import Timeout try: response = requests.get(url, timeout=1) except Timeout: print('time out !!') else: print('OK')Session
Utilisé to persist parameters across requests. For example, if you want to use the same authentication across multiple requests, you could use a session:
from getpass import getpass with requests.Session() as session: session.auth = ('username', getpass()) response = session.get(url) # Instead of requests.get(), you'll use session.get()Max Retries
from requests.adapters import HTTPAdapter from requests.exceptions import ConnectionError github_adapter = HTTPAdapter(max_retries=3) session = requests.Session() # Use `github_adapter` for all requests to endpoints that start with this URL session.mount(url, github_adapter) try: session.get(url) except ConnectionError as ce: print(ce)beautifulsoup
pip install beautifulsoup4
from bs4 import BeautifulSoup soup = BeautifulSoup(fichier_html, 'html.parser') print(soup.prettify()) # pour afficher chaque balise sur une ligne
soup.title <title>Le titre de la page</title> soup.title.name u'title' soup.title.string u'Le titre de la page' soup.title.parent.name u'head' soup.a <a href="http://bla.fr/aaa" id="a1">A</a> soup.find(id="a3") <a href="http://bla.fr/ccc" id="a3">C</a>
for link in soup.find_all('a'): print(link.get('href')) http://bla.fr/aaa http://bla.fr/bbb http://bla.fr/cccprint(soup.get_text())
with open(page) as fp: soup = BeautifulSoup(fp)tag['id'] u'boldest'tag.attrs {u'id': 'boldest'}print(soup.b.prettify())
Naviguer dans le document
Navigating using tag names
soup.head <head><title>The Dormouse's story</title></head> soup.title <title>The Dormouse's story</title>
soup.body.b <b>The Dormouse's story</b> ---> premier <b> rencontré après <body>soup.a <a href="http://example.com/elsie" id="link1">Elsie</a> ---> premier <a> rencontré dans le documentsoup.find_all('a') [<a href="http://a.fr/elsie" id="link1">Elsie</a>, <a href="http://a.fr/lacie" id="link2">Lacie</a>, <a href="http://a.fr/tillie" id="link3">Tillie</a>].contents and .children
A tag’s children are available in a list called .contents:
soup.head <head><title>The Dormouse's story</title></head> soup.head.contents [<title>The Dormouse's story</title>] soup.head.contents[0] <title>The Dormouse's story</title> soup.head.contents[0].contents [u'The Dormouse's story']
len(soup.contents) 1 soup.contents[0].name u'html'
for child in soup.head.children: print(child).descendants
for child in soup.head.descendants: print(child) <title>The Dormouse's story</title> The Dormouse's storylen(list(soup.children)) 1 len(list(soup.descendants)) 25
.string
soup.head.title.string u'The Dormouse's story'If there’s more than one thing inside a tag :
for string in soup.strings: print(repr(string)) u"The Dormouse's story" u'\n\n' u'Elsie\n' u' and\n' u'Tillie' u'...' u'\n'for string in soup.stripped_strings: print(repr(string)) u"The Dormouse's story" u'Elsie' u'and' u'Tillie' u'...'.parent
soup.title <title>The Dormouse's story</title> soup.title.parent <head><title>The Dormouse's story</title></head>
.parents
soup.a <a href="http://example.com/elsie" id="link1">Elsie</a> for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name) p body html [document] None
Going sideways
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>") print(sibling_soup.prettify()) <html> <body> <a> <b> text1 </b> <c> text2 </c> </a> </body> </html>.next_sibling and .previous_sibling
.next_sibling and .previous_sibling to navigate between page elements that are on the same level :
soup.b.next_sibling <c>text2</c> soup.c.previous_sibling <b>text1</b>
NOTE : The strings “text1” and “text2” are not siblings, because they don’t have the same parent:
sibling_soup.b.string # u'text1' print(sibling_soup.b.string.next_sibling) # None
In real documents, the .next_sibling or .previous_sibling of a tag will usually be a string containing whitespace. Going back to the “three sisters” document:
<a href="http://a.com/elsie" id="a1">Elsie</a> <a href="http://a.com/lacie" id="a2">Lacie</a> <a href="http://a.com/tillie" id="a3">Tillie</a>
You might think that the .next_sibling of the first <a> tag would be the second <a> tag. But actually, it’s a string: the comma and newline that separate the first <a> tag from the second:
link = soup.a link # <a href="http://a.com/elsie" id="link1">Elsie</a> link.next_sibling # u',\n'
The second <a> tag is actually the .next_sibling of the comma:
link.next_sibling.next_sibling # <a href="http://a.com/lacie" id="a2">Lacie</a>
.next_siblings and .previous_siblings
You can iterate over a tag’s siblings with .next_siblings or .previous_siblings:
for sibling in soup.a.next_siblings: print(repr(sibling)) # u',\n' # <a href="http://a.com/lacie" id="a2">Lacie</a> # u' and\n' # <a href="http://a.com/tillie" id="a3">Tillie</a> # u'; and they lived at the bottom of a well.' # None for sibling in soup.find(id="a3").previous_siblings: print(repr(sibling)) # ' and\n' # <a href="http://a.com/lacie" id="link2">Lacie</a> # u',\n' # <a href="http://a.com/elsie" id="link1">Elsie</a> # u'Once upon a time there were three little sisters; and their names were\n' # NoneGoing back and forth
.next_element and .previous_element
.next_element
last_a_tag = soup.find("a", id="link3") last_a_tag # <a href="http://a.com/tillie" id="link3">Tillie</a> last_a_tag.next_sibling # '; and they lived at the bottom of a well.'But the .next_element of that <a> tag, the thing that was parsed immediately after the <a> tag, is not the rest of that sentence: it’s the word “Tillie”:
last_a_tag.next_element # u'Tillie'
That’s because in the original markup, the word “Tillie” appeared before that semicolon. The parser encountered an <a> tag, then the word “Tillie”, then the closing </a> tag, then the semicolon and rest of the sentence. The semicolon is on the same level as the <a> tag, but the word “Tillie” was encountered first.
The .previous_element attribute is the exact opposite of .next_element. It points to whatever element was parsed immediately before this one:
last_a_tag.previous_element # u' and\n' last_a_tag.previous_element.next_element # <a href="http://a.com/tillie" id="link3">Tillie</a>
.next_elements and .previous_elements
for element in last_a_tag.next_elements: print(repr(element)) u'Tillie' u';\nand they lived at the bottom of a well.' u'\n\n' <p>...</p> u'...' u'\n' NoneExplorer le document
soup.find_all('b') [<b>The Dormouse's story</b>]import re for tag in soup.find_all(re.compile("^b")): print(tag.name) body bfor tag in soup.find_all(re.compile("t")): # tous les tags contenant la lettre t print(tag.name) html titlesoup.find_all(["a", "b"]) [<b>The Dormouse's story</b>, <a href="http://a.fr/A" id="a1">A</a>, <a href="http://a.fr/B" id="a2">B</a>, <a href="http://a.fr/C" id="a3">C</a>]def has_class_but_no_id(tag): return tag.has_attr('class') and not tag.has_attr('id') soup.find_all(has_class_but_no_id) [<p><b>The Dormouse's story</b></p>, <p>Once upon a time there were...</p>, <p>...</p>]
def not_lacie(href): return href and not re.compile("lacie").search(href) soup.find_all(href=not_lacie) [<a href="http://a.com/elsie" id="link1">Elsie</a>, <a href="http://a.com/tillie" id="link3">Tillie</a>]
from bs4 import NavigableString def surrounded_by_strings(tag): return (isinstance(tag.next_element, NavigableString) and isinstance(tag.previous_element, NavigableString)) for tag in soup.find_all(surrounded_by_strings): print tag.name # p # a # a # a # pfind_all()
find_all(name, attrs, recursive, string, limit, **kwargs)
soup.find_all("title") [<title>The Dormouse's story</title>] soup.find_all("p", "title") [<p><b>The Dormouse's story</b></p>] soup.find_all("a") [<a href="http://a.com/elsie" id="link1">Elsie</a>, <a href="http://a.com/lacie" id="link2">Lacie</a>, <a href="http://a.com/tillie" id="link3">Tillie</a>] soup.find_all(id="link2") [<a href="http://a.com/lacie" id="link2">Lacie</a>] import re soup.find(string=re.compile("sisters")) u'Once upon a time there were three little sisters; and their names were\n'name argument
soup.find_all("title") [<title>The Dormouse's story</title>]soup.find_all(id='link2') [<a href="http://a.com/lacie" id="link2">Lacie</a>]soup.find_all(href=re.compile("elsie")) [<a href="http://a.com/elsie" id="link1">Elsie</a>]soup.find_all(id=True) [<a href="http://a.fr/A" id="link1">A</a>, <a href="http://a.fr/B" id="link2">B</a>, <a href="http://a.fr/C" id="link3">C</a>]soup.find_all(href=re.compile("elsie"), id='link1') [<a href="http://a.fr/A" id="link1">A</a>]data_soup = BeautifulSoup('<div data-foo="value">foo!</div>') data_soup.find_all(data-foo="value") SyntaxError: keyword can't be an expressiondata_soup.find_all(attrs={"data-foo": "value"}) [<div data-foo="value">foo!</div>]name_soup = BeautifulSoup('<input name="email"/>') name_soup.find_all(name="email") [] name_soup.find_all(attrs={"name": "email"}) [<input name="email"/>]Searching by CSS class
soup.find_all("a", class_="sister") [<a href="http://a.fr/A" id="a1">A</a>, <a href="http://a.fr/B" id="a2">B</a>, <a href="http://a.fr/C" id="a3">C</a>]soup.find_all(class_=re.compile("itl")) [<p><b>The Dormouse's story</b></p>] def has_six_characters(css_class): return css_class is not None and len(css_class) == 6 soup.find_all(class_=has_six_characters) [<a href="http://a.fr/A" id="a1">A</a>, <a href="http://a.fr/B" id="a2">B</a>, <a href="http://a.fr/C" id="a3">C</a>]Remember that a single tag can have multiple values for its “class” attribute. When you search for a tag that matches a certain CSS class, you’re matching against any of its CSS classes:
css_soup = BeautifulSoup('<p></p>') css_soup.find_all("p", class_="strikeout") [<p></p>]css_soup.select("p.strikeout.body") [<p></p>]soup.find_all("a", attrs={"class": "sister"}) [<a href="http://a.fr/A" id="a1">A</a>, <a href="http://a.fr/B" id="a2">B</a>, <a href="http://a.fr/C" id="a3">C</a>]string
you can search for strings instead of tags. you can pass in a string, a regular expression, a list, a function, or the value True. Here are some examples:
soup.find_all(string="Elsie") [u'Elsie'] soup.find_all(string=["Tillie", "Elsie", "Lacie"]) [u'Elsie', u'Lacie', u'Tillie'] soup.find_all(string=re.compile("Dormouse")) [u"The Dormouse's story", u"The Dormouse's story"] def is_the_only_string_within_a_tag(s): """Return True if this string is the only child of its parent tag.""" return (s == s.parent.string) soup.find_all(string=is_the_only_string_within_a_tag) # [u"The Dormouse's story", u"The Dormouse's story", u'Elsie', u'Lacie', u'Tillie', u'...']
Although string is for finding strings, you can combine it with arguments that find tags: Beautiful Soup will find all tags whose .string matches your value for string. This code finds the <a> tags whose .string is “Elsie”:
soup.find_all("a", string="Elsie") [<a href="http://a.fr/A" id="a1">A</a>]The string argument is new in Beautiful Soup 4.4.0. In earlier versions it was called text:
soup.find_all("a", text="Elsie") [<a href="http://a.fr/A" id="a1">A</a>]limit
soup.find_all("a", limit=2) [<a href="http://a.fr/A" id="a1">A</a>, <a href="http://a.fr/B" id="a2">B</a>]recursive
La récursivité est True par défaut. Donc, va chercher dans les enfants des enfants des enfants… Sinon, utiliser recursive=False.
Calling a tag is like calling find_all()
find_all() a un raccourci :
soup.find_all("a") soup("a")soup.title.find_all(string=True) soup.title(string=True)
find()
soup.find('title') # <title>The Dormouse's story</title>The only difference is that find_all() returns a list containing the single result, and find() just returns the result.
If find_all() can’t find anything, it returns an empty list. If find() can’t find anything, it returns None:
print(soup.find("nosuchtag")) # NoneRemember the soup.head.title trick from Navigating using tag names? That trick works by repeatedly calling find():
soup.head.title # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title>find_parents() and find_parent()
a_string = soup.find(string="Lacie") a_string u'Lacie' a_string.find_parents("a") [<a href="http://a.com/lacie" id="link2">Lacie</a>] a_string.find_parent("p") <p>Once upon a time there were three little sisters; and their names were <a href="http://a.com/elsie" id="link1">Elsie</a>, <a href="http://a.com/lacie" id="link2">Lacie</a> and <a href="http://a.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> a_string.find_parents("p",) []
These search methods actually use .parents to iterate over all the parents, and check each one against the provided filter to see if it matches.
find_next_siblings() et find_next_sibling()
first_link = soup.a first_link <a href="http://a.com/elsie" id="link1">Elsie</a> first_link.find_next_siblings("a") [<a href="http://a.com/lacie" id="link2">Lacie</a>, <a href="http://a.com/tillie" id="link3">Tillie</a>] soup.find("p", "story").find_next_sibling("p") <p>...</p>
find_previous_siblings() et find_previous_sibling()
These methods use .previous_siblings to iterate over an element’s siblings that precede it in the tree.
last_link = soup.find("a", id="link3") last_link <a href="http://a.com/tillie" id="link3">Tillie</a> last_link.find_previous_siblings("a") [<a href="http://a.com/lacie" id="link2">Lacie</a>, <a href="http://a.com/elsie" id="link1">Elsie</a>] soup.find("p", "story").find_previous_sibling("p") <p><b>The Dormouse's story</b></p>find_all_next() and find_next()
These methods use .next_elements to iterate over whatever tags and strings that come after it in the document.
first_link = soup.a first_link # <a href="http://a.com/elsie" id="link1">Elsie</a> first_link.find_all_next(string=True) # [u'Elsie', u',\n', u'Lacie', u' and\n', u'Tillie', # u';\nand they lived at the bottom of a well.', u'\n\n', u'...', u'\n'] first_link.find_next("p") # <p>...</p>find_all_previous() and find_previous()
These methods use .previous_elements to iterate over the tags and strings that came before it in the document.
first_link = soup.a first_link # <a href="http://a.com/elsie" id="link1">Elsie</a> first_link.find_all_previous("p") # [<p>Once upon a time there were three little sisters; ...</p>, # <p><b>The Dormouse's story</b></p>] first_link.find_previous("title") # <title>The Dormouse's story</title>CSS selectors
.select() method which uses SoupSieve to run a CSS selector against a parsed document and return all the matching elements. Tag has a similar method which runs a CSS selector against the contents of a single tag.
soup.select("title") # [<title>The Dormouse's story</title>] soup.select("p:nth-of-type(3)") # [<p>...</p>]soup.select("body a") # [<a href="http://a.com/elsie" id="link1">Elsie</a>, # <a href="http://a.com/lacie" id="link2">Lacie</a>, # <a href="http://a.com/tillie" id="link3">Tillie</a>] soup.select("html head title") # [<title>The Dormouse's story</title>]soup.select("head > title") # [<title>The Dormouse's story</title>] soup.select("p > a") # [<a href="http://a.com/A" id="a1">A</a>, # <a href="http://a.com/B" id="a2">B</a>, # <a href="http://a.com/tillie" id="a3">Tillie</a>] soup.select("p > a:nth-of-type(2)") # [<a href="http://a.com/B" id="a2">B</a>] soup.select("p > #a1") # [<a href="http://a.com/A" id="a1">A</a>] soup.select("body > a") # []Find the siblings of tags:
soup.select("#a1 ~ .sister") # [<a href="http://a.com/B" id="a2">B</a>, # <a href="http://a.com/C" id="a3">C</a>] soup.select("#link1 + .sister") # [<a href="http://a.com/B" id="a2">B</a>]Find tags by CSS class:
soup.select(".sister") # [<a href="http://a.com/A" id="link1">A</a>, # <a href="http://a.com/lacie" id="link2">Lacie</a>, # <a href="http://a.com/tillie" id="link3">Tillie</a>] soup.select("[class~=sister]") # [<a href="http://a.com/A" id="link1">A</a>, # <a href="http://a.com/lacie" id="link2">Lacie</a>, # <a href="http://a.com/tillie" id="link3">Tillie</a>]Find tags by ID:
soup.select("#link1") # [<a href="http://a.com/A" id="link1">A</a>] soup.select("a#link2") # [<a href="http://a.com/lacie" id="link2">Lacie</a>]Find tags that match any selector from a list of selectors:
soup.select("#link1,#link2") # [<a href="http://a.com/A" id="link1">A</a>, # <a href="http://a.com/lacie" id="link2">Lacie</a>]Test for the existence of an attribute:
soup.select('a[href]') [<a href="http://a.com/A" id="a1">A</a>, <a href="http://a.com/lacie" id="a2">Lacie</a>, <a href="http://a.com/tillie" id="a3">Tillie</a>]Find tags by attribute value:
soup.select('a[href="http://a.com/A"]') # [<a href="http://a.com/A" id="a1">A</a>] soup.select('a[href^="http://a.com/"]') # [<a href="http://a.com/A" id="a1">A</a>, # <a href="http://a.com/lacie" id="a2">Lacie</a>, # <a href="http://a.com/tillie" id="a3">Tillie</a>] soup.select('a[href$="tillie"]') # [<a href="http://a.com/tillie" id="a3">Tillie</a>] soup.select('a[href*=".com/el"]') # [<a href="http://a.com/A" id="a1">A</a>]There’s also a method called select_one(), which finds only the first tag that matches a selector:
soup.select_one(".sister") # <a href="http://a.com/A" id="a1">A</a>Output
Pretty-printing
The prettify() method will turn a Beautiful Soup parse tree into a nicely formatted Unicode string, with a separate line for each tag and each string:
markup = '<a href="http://a.com/">I linked to <i>a.com</i></a>' soup = BeautifulSoup(markup) soup.prettify() # '<html>\n <head>\n </head>\n <body>\n <a href="http://a.com/">\n...' print(soup.prettify()) # <html> # <head> # </head> # <body> # <a href="http://a.com/"> # I linked to # <i> # example.com # </i> # </a> # </body> # </html>
get_text()
markup = '<a href="http://a.com/">\nI linked to <i>a.com</i>\n</a>' soup = BeautifulSoup(markup) soup.get_text() u'\nI linked to a.com\n' soup.i.get_text() u'example.com'
You can specify a string to be used to join the bits of text together:
# soup.get_text("|") u'\nI linked to |a.com|\n'You can tell Beautiful Soup to strip whitespace from the beginning and end of each bit of text:
# soup.get_text("|", strip=True) u'I linked to|a.com'But at that point you might want to use the .stripped_strings generator instead, and process the text yourself:
[text for text in soup.stripped_strings] # [u'I linked to', u'a.com']
Les différents parser
BeautifulSoup("<a></p>", "lxml") <html><body><a></a></body></html>BeautifulSoup("<a></p>", "html5lib") <html><head></head><body><a><p></p></a></body></html>BeautifulSoup("<a></p>", "html.parser") <a></a>Parsing only part of a document
SoupStrainer choose which parts of an incoming document are parsed. You just create a SoupStrainer and pass it in to the BeautifulSoup constructor as the parse_only argument.
Note : donn’t work avec html5lib parser.
SoupStrainer
The SoupStrainer class takes the same arguments as a typical method from Searching the tree: name, attrs, string. Here are three SoupStrainer objects:
from bs4 import SoupStrainer only_a_tags = SoupStrainer("a") only_tags_with_id_link2 = SoupStrainer(id="link2") def is_short_string(string): return len(string) < 10 only_short_strings = SoupStrainer(string=is_short_string)print(BeautifulSoup(html_doc, "html.parser", parse_only=only_a_tags).prettify()) print(BeautifulSoup(html_doc, "html.parser", parse_only=only_tags_with_id_link2).prettify()) print(BeautifulSoup(html_doc, "html.parser", parse_only=only_short_strings).prettify())
You can also pass a SoupStrainer into any of the methods covered in Searching the tree. This probably isn’t terribly useful, but I thought I’d mention it:
soup = BeautifulSoup(html_doc) soup.find_all(only_short_strings) [u'\n\n', u'\n\n', u'Elsie', u',\n', u'Lacie', u' and\n', u'Tillie', u'\n\n', u'...', u'\n']EXEMPLE : VIDEO SUR D8
Exemple avec une vidéo de D8. Dans le code source de la page, on voit que la partie qui contient videoId est courte. Ici l’identifiant recherché est 943696
import requests import bs4 as BeautifulSoup html = requests.get('http://www.d8.tv/d8-series/pid6654-d8-longmire.html') soup = BeautifulSoup.BeautifulSoup(html)print(soup.prettify())
BeautifulSoup permet de multiples syntaxes, par exemple, on n’est pas obligé de donner le chemin complet
soup.meta
soup.meta['http-equiv'] 'Content-Type'soup.meta.find_next_sibling() '<meta content="D8" name="author"/>' soup.meta.find_next_sibling()['content'] 'D8' soup.meta.find_next_sibling()['name'] 'author'
soup.find('div')soup.find_all('div')soup.find('div',attrs={"class":u"block-common block-player-programme"}) <div> <div> <div> <div itemprop="video" itemscope itemtype="http://schema.org/VideoObject"> <h1>Vidéo : <span itemprop="name">Longmire - Samedi 30 novembre à 20h50</span></h1> <meta itemprop="duration" content="" /> <meta itemprop="thumbnailUrl" content="http://site.com/wwwplus/image/53/1/1/LONGMIRE_131120_UGC_3279_image_L.jpg" /> <meta itemprop="embedURL" content="http://site.fr/embed/flash/CanalPlayerEmbarque.swf?vid=975153" /> <meta itemprop="uploadDate" content="2013-11-29T00:00:00+01:00" /> <meta itemprop="expires" content="2014-02-18T00:00:00+01:00" /> <canal:player videoId="975153" width="640" height="360" id="CanalPlayerEmbarque"></canal:player>canal:player
soup.find('div',attrs={"class":u"block-common block-player-programme"}).find('canal:player') '<canal:player height="360" id="CanalPlayerEmbarque" videoid="786679" width="640"></canal:player>' soup.findAll('div', attrs={"class":u"tlog-inner"}) [<div class="tlog-inner"> <div class="tlog-account"> <span class="tlog-avatar"><img height="30" src="http://site.com/design/d8/images/xtrans.gif" width="30"/></span> <a class="tlog-logout le_btn" href="#">x</a> </div> <form action="#" method="post"> <label class="switch-fb"> <span class="cursor traa"> </span> <input checked="" id="check-switch-fb" name="switch-fb" type="checkbox" value="1"/> </label> </form> <div id="headerFbLastActivity"> <input id="name_facebook_user" type="hidden"/> <div class="top-arrow"></div> <div class="top"> <div class="top-bg"></div> <div class="top-title">Activité récente</div> </div> <div class="middle"> <div class="wrap-last-activity"> <div class="entry">Aucune</div> </div> <div class="wrap-notification"></div> </div> <div class="bottom"> <a class="logout" href="#logout">Déconnexion</a> </div> </div> </div>]On peut prendre le premier élément de cette liste
soup.findAll('div', attrs={"class":u"tlog-inner"})[0]et ne vouloir que la ligne commençant par “span class”
soup.findAll('div', attrs={"class":u"tlog-inner"})[0].spance qui affiche
<span><img height="30" src="http://media.canal-plus.com/design/front_office_d8/images/xtrans.gif" width="30"/></span>
Nous voulons maintenant juste ce qui suit videoId.
dir(soup.find('div',attrs={"class":u"block-common block-player-programme"}).find('canal:player'))montre, entre autres choses, que la méthode get est disponible.
Pour récupérer l’identifiant qui nous intéresse, on peut donc fairesoup.find('div',attrs={"class":u"block-common block-player-programme"}).find('canal:player').get('videoid') '975153'ou utiliser une autre syntaxe
soup.find('div',attrs={"class":u"block-common block-player-programme"}).find('canal:player')['videoid'] '975153'De la même manière, on peut récupérer le titre de la vidéo
soup.find('h3',attrs={"class":u"bpp-title"}) '<h3>Longmire - Samedi 30 novembre à 20h50</h3>'mais on veut juste le titre, donc
soup.find('h3',attrs={"class":u"bpp-title"}).text uu'Longmire - Samedi 30 novembre \xe0 20h50'Maintenant que l’on a le numéro de la vidéo, on peut le passer au site qui contient l’adresse, et avec un peu de scripting XML, récupérer l’adresse de la vidéo
Selon que la vidéo vient de D8 ou de canal, elle sera sur vidéo de d8 ou vidéo de Canal Plus et avec un peu de codefrom lxml import objectify def get_HD(d8_cplus,vid): root = objectify.fromstring(urlopen('http://service.canal-plus.com/video/rest/getVideosLiees/'+d8_cplus+'/'+vid).read()) for x in root.iter(): if x.tag == 'VIDEO' and x.ID.text == vid: for vres in vidattr: if hasattr(x.MEDIA.VIDEOS, vres): print 'Resolution :', vres videoUrl = getattr(x.MEDIA.VIDEOS, vres).text break break print videoUrl for x in ['d8','cplus']: get_HD(x,vid)on peut trouver l’adresse de la vidéo.
Il reste juste à envoyer la commande rtmpdump, dans ce casrtmpdump -r rtmp://ugc-vod-fms.canalplus.fr/ondemand/videos/1311/MIRE_131120_UGC_3279_video_HD.mp4 -c 1935 -m 10 -B 1 -o mavideo.mp4
les enfants d’un tag sont disponibles dans une liste appelée .contents.has_key(‘value’) vous rendra de grands services, associé parfois à
['value'] != u''
pour extraire un tag sans attribut, par exemple pour un tag p, la syntaxe sera simplement
soup.findAll('p', {'class': None}).attrs vous affichera un dictionnaire qui peut être intéressant, par exemple :
soup.head.link '<link href="http://media.canal-plus.com/design_pack/d8/css/d8.d.min.css" rel="stylesheet" type="text/css"/>' soup.head.link.attrs {'href': 'http://media.canal-plus.com/design_pack/d8/css/d8.dmin.css', 'type': 'text/css', 'rel': ['stylesheet']}
.previousSibling (et .next_sibling) peut être utile, par exemple, avec un simple HTML comme ce qui suit
<div> Category: <a href="/category/personal">Personal</a> </div>
on peut récupérer la chaîne Category : de plusieurs manières, par exemple l’évident
soup.findAll('div')[0].contents[0] u'\n Category:\n'mais aussi en remontant depuis la balise a
soup.find('a').previousSibling u'\n Category:\n'Sinon cela est aussi utile avec un HTML mal foutu comme
<p>z1</p>tagada <p>z2</p>tsointsoin
Dans ce cas, pour récupérer tagada tsointsoin
on fera par exemplesoup.findAll('p')[0].next_sibling soup.findAll('p')[1].next_siblingou, pour faire plaisir à Sam/Max
[p.next_sibling for p in soup.findAll('p')] [u'tagada', u'tsoitsoin']A quoi sert text=True ?
Simplement à récupérer juste du texte dans du Html, sans toute la syntaxe HTML.
Un exemple, toujours sur la vidéo de D8 va illustrer celasoup.findAll('div', {"class":"tmlog-wdrw wdrw"})[0].a '<a href="#">' '<span>Se connecter</span>' '</a>' soup.findAll('div', {"class":"tmlog-wdrw wdrw"})[0].a.contents [u'\n', <span>Se connecter</span>, u'\n'] soup.findAll('div', {"class":"tmlog-wdrw wdrw"})[0].a.text u'\nSe connecter\n' soup.findAll('div', {"class":"tmlog-wdrw wdrw"})[0].a.findAll(text=True) [u'\n', u'Se connecter', u'\n']RECUPERER LE HREF D’UN LIEN
for a in soup.find_all('a', href=True): print("lien:", a['href']) lien: https://some_url.com lien: https://some_other_url.com
links_with_text = [] for a in soup.find_all('a', href=True): if a.text: links_with_text.append(a['href'])
links_with_text = [a['href'] for a in soup.find_all('a', href=True) if a.text]
tags = soup.find_all(lambda tag: tag.name == 'a' and tag.get('href') and tag.text)
links = [a['href'] for a in soup.find_all('a', href=True)]
links = [a['href'] for a in soup.select('a[href]')]
Récupérer l’information d’une balise HTML précise
ospour gérer la pause à la fin du scriptcsvpour exporter les données scrappées dans un fichier CSVimport os import csv import requests from bs4 import BeautifulSoup
url="https://zestedesavoir.com/tutoriels/?category=autres-informatique"requete = requests.get(url) page = requete.content soup = BeautifulSoup(page)
Récupérer le texte du premier titre <h1> :
h1 = soup.find("h1", {"class": "ico-after ico-tutos"}) print(h1.string)titre = h1.string.strip() # .strip() pour supprimer les espaces entourantsRécupérer le titre et le descriptif de chaque tutoriel :
h3 = soup.find_all("h3", {"class": "content-title"}) desc = soup.find_all("p", {"class": "content-description"}) liste_titre = [elt.string.strip() for elt in h3] liste_description = [elt.string.strip() for elt in desc]Extraire les données dans un fichier CSV :
j = len(liste_titre) i = 0 with open("donnees.csv", "w", encoding="utf-8") as fichier writer = csv.writer(fichier) while i < j: writer.writerow((liste_titre[i], liste_description[i])) i+=1writer.writerow(())double parenthèse au fait que nous utilisons un tuple en argument ici. Comme un tuple est noté à l’intérieur de parenthèse, il y a donc ici une double parenthèse.Obtenir le titre, les titres et les liens
soup.h1 # <h1 id="firstHeading" lang="en">Python (programming language)</h1> soup.h1.string # 'Python (programming language)' soup.h1['class'] # ['firstHeading'] soup.h1['id'] # 'firstHeading' soup.h1.attrs # {'class': ['firstHeading'], 'id': 'firstHeading', 'lang': 'en'}for h in soup.find_all('h2'): print(h.text)Navigation dans le DOM
1er lien dans le 1er paragraphe =
soup.p.aTous les liens du 1er paragraphe =
soup.p.find_all(‘a’)Tous les enfants d’une étiquette en tant que liste =
tag.contentsEnfants à un index spécifique =
tag.contents[index]..childrenutile pour accéder aux descendants directs ou de premier niveau d’une étiquette.Tous les descendants =
.descendantsprint(soup.p.contents)
# [<b>Python</b>, ' is a widely used ',.....the full list]
print(soup.p.contents[10])
# <a href="/wiki/Readability" title="Readability">readability</a>
for child in soup.p.children:
print(child.name)
Parent d’un élément = .parent
Tous les ancêtres d’un élément = .parents
soup.p.parent.name for parent in soup.p.parents: print(parent.name)Frères et sœurs précédents et suivants d’un élément = .previous_sibling et .next_sibling.
Tous les frères et sœurs d’un élément = .previous_siblings et .next_siblings.
soup.p.a.next_sibling
soup.p.a.previous_sibling
élément immédiatement après = .next_element
élément immédiatement avant = .previous_element
tous les éléments précédents et après = .previous_elements et .next_elements
Parsing a page with BeautifulSoup
from bs4 import BeautifulSoup
page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser')print(soup.prettify())
soup.p.get_text()
soup.find_all('p')soup.find_all('p')[0].get_text()soup.find('p')chercher par class et id
soup.find_all('p', class_='outer-text')soup.find_all(class_="outer-text")soup.find_all(id="first")Chercher par les Selectors CSS
p a toutes les balises a dans une balise p
p.outer-text — finds all p tags with a class of outer-textp#first — finds all p tags with an id of first.
body p.outer-text — finds any p tags with a class of outer-text inside of a body tag.
soup.select("div p") [<p class="inner-text first-item" id="first">First paragraph.</p>, <p class="inner-text">Second paragraph.</p>]select renvoie une list comme find and find_all.
BeautifulSoup
from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc) for p in soup.find_all('p'): print pLire les attributs
for p in soup.find_all('p'): print p.get("class")Les méthodes de la classe BeautifulSoup
clear ( decompose=False )Extrait tous les enfantsdecode_contents(indent_level=None, eventual_encoding=’utf-8′, formatter=’minimal’)Créer un rendu en chaine unicodedecompose ( ) Detruit récursivement les contenus de l’arbre
encode(encoding=’utf-8′, indent_level=None, formatter=’minimal’, errors=’xmlcharrefreplace’ )encodeencode_contents ( indent_level=None, encoding=’utf-8′, formatter=’minimal’ ) Créer des rendus du tag en bytestring
find(name=None, attrs={}, recursive=True, text=None)Retourne seulement le premier enfant de la balise correspondant pour le critère donnéfind_all(name=None, attrs={}, recursive=True, text=None, limit=None)Retourne une liste d’objet balise correspondant à la demande.find ( name=None, attrs={}, recursive=True, text=None, **kwargs ) Retourne seulement le premier enfant de la balise cherchée
findChildren ( name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs ) Retourne une liste d’objet balise correspondant à la demande
get ( key, default=None ) Retourne la valeur de l’attribut "key" de la balise ou retourne la valeur default
get_text ( self, separator=u'’, strip=False) Retourne toutes les chaines de caractères des enfants concaténé utilisant le séparateur indiqué
has_attr ( key ) True si l’attribut demandé est présent
has_key ( key ) Vérifie la présence de la clé
index ( element ) Retourne l’index de l’élément
prettify ( self, encoding=None, formatter=’minimal’ ) Améliore la lecture du code
recursiveChildGenerator ( )
append ( self, tag ) Ajoute la balise donnée à l’objet en cours
extract ( ) Extrait l’élément de l’arbre
find_next_siblings ( ) Renvoi les objects frères de l’objet en cours
find_parents () Renvoi les parents
find_all_previous () Retourne tous les items qui match avec le critère donné avant l’objet en cours
find_previous_siblings () Retourne les objets frères de l’objet en cours qui sont avant celui-ci
find_all_next () Retourne les objets qui correspondent à la recherche mais qui se situent après l’objet en cours
find_all_previous () Retourne les objets qui correspondent à la recherche mais qui se situent avant l’objet en cours
find_next ( self, name=None, attrs={}, text=None, **kwargs ) Retourne le premier objet frère après l’objet en cours
find_next_sibling ( self, name=None, attrs={}, text=None, **kwargs ) Retourne l’objet frère le plus proche après lui
find_next_siblings ( self, name=None, attrs={}, text=None, limit=None, **kwargs ) Retourne les objets frères suivants
find_parent ( self, name=None, attrs={}, **kwargs ) Retourne le parent le plus proche
find_parents ( self, name=None, attrs={}, limit=None, **kwargs ) Retourne les parents
find_previous ( self, name=None, attrs={}, text=None, **kwargs ) Retourne le premier item avant l’objet en cours
find_previous_sibling ( self, name=None, attrs={}, text=None, **kwargs ) Retourne l’item frère le plus proche précédent l’objet en cours
find_previous_siblings ( self, name=None, attrs={}, text=None, limit=None, **kwargs ) Retourne les items frères les plus proches précédents l’objet en cours
find_all_next ( self, name=None, attrs={}, text=None, limit=None, **kwargs ) Retourne tous les items qui suivent l’objet en cours
find_all_previous ( self, name=None, attrs={}, text=None, limit=None, **kwargs ) Retourne tous les items qui précédent l’objet en cours
Exemple d’utilisation
J’avais besoin d’un parseur HTML pour mettre en forme et colorer le code que je présente sur ce site; je partage ce petit script:
# coding: utf-8 import sys import glob from bs4 import BeautifulSoup from pygments import highlight from pygments.lexers import PythonLexer from pygments.formatters import HtmlFormatter def pygments_file(pathname): # On ouvre le fichier with open(pathname, "r" ) as f: html_doc = f.read() soup = BeautifulSoup(html_doc) # On boucle sur les pre trouvés for pre in soup.find_all('pre'): try: if "code" in pre.get("class"): texte = highlight(pre.get_text(), PythonLexer(), \ HtmlFormatter(nowrap=True)) n = BeautifulSoup('%s' % texte) pre.replace_with(n.body.contents[0]) except: print("Erreur avec {}".format(pre,)) if soup.body: with open(pathname, "w") as f: f.write(soup.body.encode_contents()) p = "/home/olivier/*.html" if sys.argv[1]: p = str(sys.argv[1]) pathnames = glob.glob(p) for pathname in pathnames: pygments_file(pathname)Vous pouvez aussi bien lui renseigner un dossier qu’un seul fichier.
Parser du HTML avec BeautifulSoup
Elles ne sont pas fragmentées les videos dans la VOD de D8 ? Parce que la commande rtpmdump me renvoie qu’une portion…
La plupart des sites de replay se téléchargent avec rtmpdump, certains avec juste un wget/curl/msdl.
Vérifie si rtmpdump et librtmpdump sont bien installés, et si la version est la même pour les 2 (2.4 pour moi).
html_page = urllib.request.urlopen(the_uri) soup = bs4.BeautifulSoup(html_page, 'html.parser') LinkList = [] for Link in soup.find_all('a'): LinkFound=Link.get('href') LinkList.append(LinkFound) print ("nombre d'URL : ",len(LinkList)) print (LinkList) “”” chaine = “-“.join(LinkList) if ("contact" in chaine) : print ("URL Contact") “””—
EXEMPLE : FILMOGRAPHIE DE CHAPLIN
récupérer tous les films où Charles Chaplin a joué en prenant comme source d’information le site IMDb.
1 - récupérer l’adresse de la fiche de Charles Chaplin sur le site de IMDb : http://www.imdb.com/name/nm0000122/.
2 - récupérer un tag, une class ou encore un id qui nous permet de différencier les balises entourant les films dans lequel il a tourné de toutes les autres informations présentes sur la page.
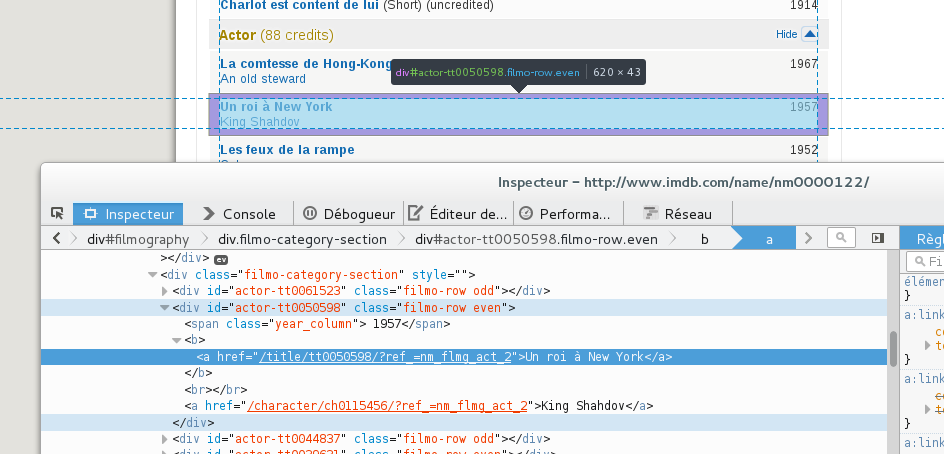
nous pouvons voir que les films, où il a été acteur, sont contenus dans un div ayant un id commençant par actor-. Nous voyons aussi que l’année du film est présente dans un sous-élément ayant dans l’attribut class la valeur year_column et le nom du film est contenu dans un balise <b>. Nous avons tous les éléments pour récupérer nos données et cela nous donne le morceau de script suivant :
Récupération de la liste de film de Charles Chaplin sur IMDB
import bs4 import re import urllib.request actor_url = 'http://www.imdb.com/name/nm0000122/' with urllib.request.urlopen(actor_url) as f: data = f.read().decode('utf-8') soup = bs4.BeautifulSoup(data, 'html.parser') for d in soup.find_all(id=re.compile('^actor-.*')): year = d.find(class_='year_column').get_text(' ', strip=True) name = d.b.get_text(' ', strip=True) print(year, name)ligne 11, nous recherchons l’ensemble des éléments ayant un id commençant par actor-. Comme vous pouvez le constater BeautifulSoup accepte l’utilisation d’expressions régulières en entrée ce qui nous permet de faire des recherches très précises. Nous parcourons l’ensemble des réponses.
ligne 12, nous demandons de nous fournir le contenu textuel du premier élément ayant comme classe year_column.
ligne 14, nous récupérons le texte contenu au sein de la balise <b>